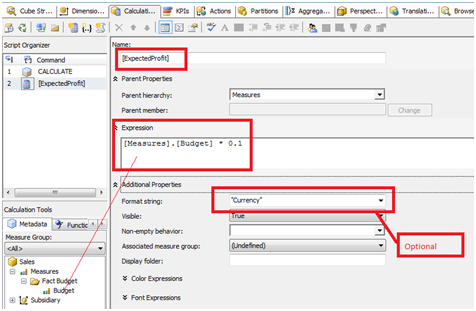
1.
Background
The
purpose of this document is to provide details on importance of aggregation, how
effectively we can design aggregations, performance monitoring & usage
based aggregation.
2.
What is Aggregation and why
build aggregation
The aggregations
are the high level summaries of data. It is analogous to calculated value by
GROUP BY statements of T-SQL with some attributes. SQL Server pre-aggregates
the measures with respect to dimension attributes at some extent instead of
executing the query runtime. Pre-aggregation improve the query performance.
Following
are the reasons to build the aggregation:
I.
Performance is the top priority of all the OLAP system
and having aggregated data will helpful to easily retrieve the data. e.g. if we
aggregate the yearly data based on days in a year. Cube has to aggregate a
large no. of columns. In place of days wise, if we have aggregated data up to
months or quarter, we will get yearly aggregated data more quickly.
II.
Aggregations improve query performance by limiting the
amount of partition data that needs to be scanned to answer a query. Instead of
querying the fact level data of the partition, SSAS will query the aggregation
and because the amount of data in the aggregation is smaller, the query can be
answered more succinctly
3.
How to do logging and
Performance monitoring
1.
To enable the logging, go to analysis service instance
where your cube exists, Right click on the server èProperties
By default, Analysis
Services does not log queries into the query log table. To log queries, you
need to set Analysis Services properties. Change the below properties to enable
logging:
I.
Create QueryLog table è True will create a table
named OLAPqueryLog in DB based on connection string in
QueryLogConnectionstring.
II.
QueryLogConnectionstring will contain the ConnectionString
e.g Server name & DB name to create log table
III.
QueryLog sampling: The default value for this property is
10, meaning that 1 out of every 10 server queries is logged. I set to 1 to log
all the queries hit to cube.
2.
To Check whether table is created or not, connect the
OLTP server & DB based on ConnectionString provided and check whether table is available or not:
Table is
created.
3.
Browse the cube and check whether query information is
logging into table or not. Start the SQL server profiler also to see the query
performance:
Checking the logging information:
I
have browsed the cube for End Customer revenue fact and logging information
with fact name & query execution duration is properly logged in the
OlapQueryLog table.
By
using OLAPQueryLog table, we can get information about facts on which users are
mostly interested and frequently called facts
4.
Check the profiler for the logged information:
4.
How to design aggregation
Based on the above
statistical data, if we feel that query is taking time and performance of the
query can be improved. In this case, we can go for the designing aggregation
for Fact EndCustomerRevenue.
I.
For designing the aggregation, open the cube solution and
go to Aggregation tabè End Customer Revenue
fact. Here it is showing ‘unassigned aggregation design’, it means there is
explicitly aggregation designed for this fact.
II.
Select ‘Design Aggregations’ to design aggregation. It
will start the aggregation design wizard
Click next
III.
It will open Review Aggregation Usage window. Here if we
want to exclude any dimension attributes from aggregation, we can remove it to
avoid unnecessary aggregation.
The options are Default, Full, None, and Unrestricted. Full means that the
attribute must be included in every aggregation, while None means that the
attribute will not be in any aggregation. Default means that the SSAS engine
will examine the attribute and associated relationships and try to determine
whether or not to include that attribute in aggregations using a set of
internal rules. These rules are very restrictive and a lot of attributes get
excluded from consideration. Unrestricted means that the attribute will be
considered without regard to the internal set of rules. For the first creation
of aggregations, I just leave all attributes set to Default. We will keep analyze our cube and accordingly
will change the usage configuration of the aggregation. Click next
IV.
It will open the object count window, either we can enter
the estimated count value or wizard will automatically count the row. Entering
count values manually will be good in case of bulk amount of data because
wizard may take lot of time to count. While specifying the value manually, make
sure value should be nearer to exact count because the Aggregation Design
Wizard uses the object counts to estimate storage requirements.
Click on count to get the
estimated count
V.
Next is Aggregation option. It will provide an option to
design aggregation with respect to storage space or performance point of view.
In designing our cube, you will have to balance the
storage needs of the aggregation tables against the speed and performance of
the queries. The three approaches to achieving this balance are as follows:
·
Set the storage size and let Microsoft® SQL Server Analysis
Services determine which aggregations to store. This approach works well when
you have limited storage space.
·
Set the percentage of performance gain and let the
necessary aggregation tables take as much storage space as they need.
·
I click Stop: Manually determine the best balance by
watching the progress of the Performance vs. Size graph.
I am selecting Performance gain because for many
applications, performance is more important as compared to storage space and
Cube processing time.
VI.
Click start to design aggregation
It creates 274 aggregations
with occupying 446.5MB disk space. Save the aggregation name. We can either
deploy the changes now or we can save only. Click finish.
VII.
In the Cube aggregation tab, we can see the designed
aggregation:
5.
Monitor the performance of the
cube after aggregation design
Deploy the designed aggregation and
check the query performance by using profiler:
Fact End
Customer Revenue:
Fig showing query execution duration
before designing aggregation- 7952 Secs
Fig showing query execution duration
after designing aggregation- 4000 Secs
Now the same query that we executed in
section 3.4 taking only 4000 seconds
Net New
Quota
Fig showing the query execution
duration before designing aggregation- 1484 secs
Fig showing the query execution
duration after designing aggregation- 1484 secs
True up
Fig showing the query execution
duration before designing aggregation- 1344
Fig showing the query execution
duration after designing aggregation- 953
6.
Usage based optimization
The problem with the
Aggregation Design Wizard is that it assumes all queries are equallylikely. Therefore,
some of the aggregations it designs are likely to be useful, but some will not
be. More importantly, there will be aggregations you need that are not created
by the Aggregation design wizard. To create those aggregations that are
required but aggregation wizard does not created, we can use usage based
optimization.
Click on the advance view
under aggregation view:
It will display the aggregation designed with
respect to dimension attributes:
Based on the logging information, if
we found that we need some more aggregation then we can check the box against
the associated dimension attributes. If
we feel some of the aggregations are not required and wizard is creating
unnecessary, in this case, we can uncheck it. Removing unnecessary aggregations
will helpful to manage disk space for the partitions as well as it reduce the
cube process time.
7.
Disadvantages of more no. of
aggregations
i.
Storage space required for the aggregated table is more.
ii.
Processing time for the cube is more.
8. Conclusion
By using
the above steps, we can understand how to design aggregation to improve cube
query performance and based on user’s action, we can do optimize the
aggregation to provide best performance and adequate disk storage to the cube.
----------------------------------------End
of Document---------------------------------------------